Overview
Overview of BEHAVIOR Vision Suite (BVS), our proposed toolkit for computer vision research. BVS builds upon the extended object assets and scene instances from BEHAVIOR-1K, and provides a customizable data generator that allows users to generate photorealistic, physically plausible labeled data in a controlled manner. We demonstrate BVS with three representative applications.

Extended BEHAVIOR-1K assets
Covering a wide range of object categories and scene types, our 3D assets have high visual and physical fidelity and rich annotations of semantic properties, allowing us to generate 1,000+ realistic scene configurations.
Scene Instance Augmentation
We enables the generation of diverse scene variations by altering furniture object models and incorporating additional everyday objects. Specifically, it can swap scene objects with alternative models from the same category, which are grouped based on visual and functional similarities. This randomization significantly varies scene appearances while maintaining layouts’ semantic integrity.
Application: Holistic Scene Understanding
One of the major advantages of synthetic datasets, including BVS, is that they offer various types of labels (segmentation masks, depth maps, and bounding boxes) for the same sets of input images. We believe that this feature can fuel the development of versatile vision models that can perform multiple perception tasks at the same time in the future.
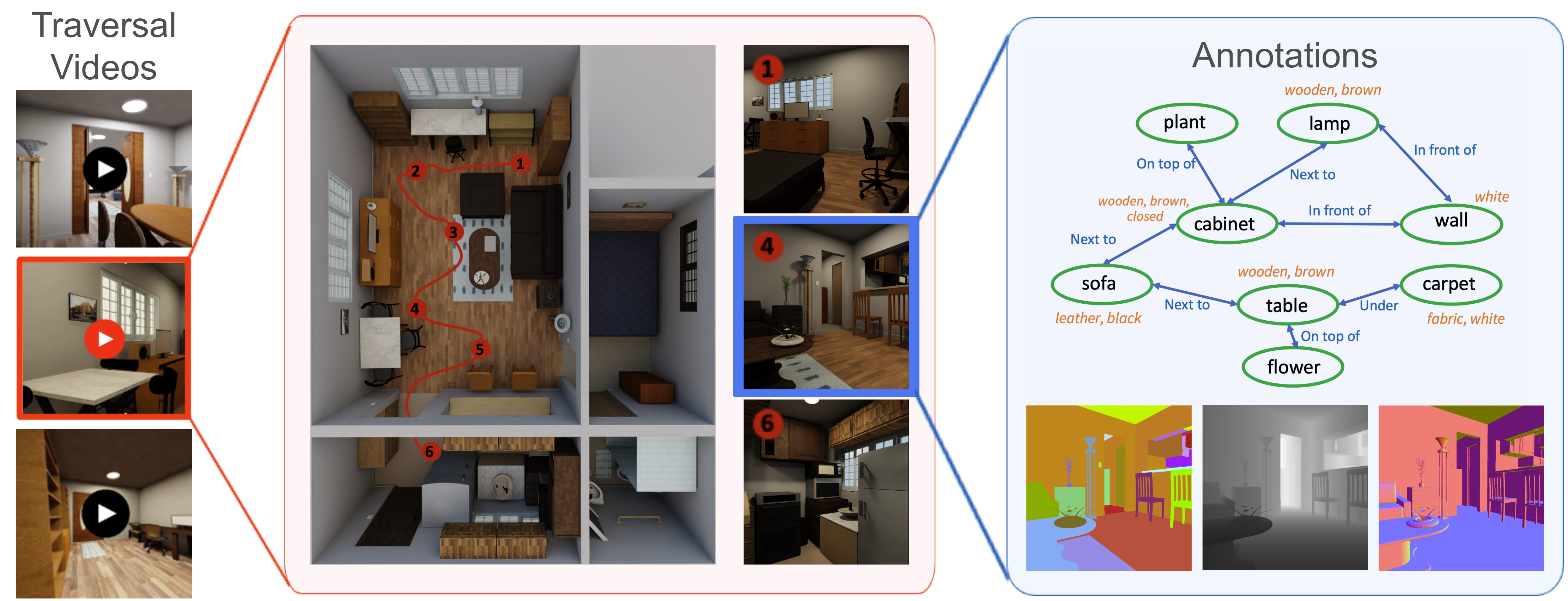
Holistic Scene Understanding Dataset. We generated extensive traversal videos across representative scenes, each with 10+ camera trajectories.For each image, BVS generates various labels (e.g., scene graphs, segmentation masks, depth).
Application: Parametric Model Evaluation
Parametric model evaluation is essential for developing and understanding perception models, enabling a systematic assessment of performance robustness against various domain shifts. Leveraging the flexibility of the simulator, our generator extends parametric evaluation to more diverse axes, including scene, camera, and object state changes.
Parametric Model Evaluation - Articulation.
Parametric Model Evaluation - Visibility.
Parametric Model Evaluation - Lighting.
Parametric Model Evaluation - Zoom.
Parametric Model Evaluation - Pitch.
Application: Object States and Relations Prediction
Users can also leverage BVS to generate training data with specific object configurations that are difficult to accumulate or annotate in the real world. We illustrates BVS’s practical application in synthesizing a dataset that facilitates the training of a vision model capable of zero-shot transfer to real-world images on the task of object relationship prediction.

Object relationship prediction model trained with BVS generated data.
Conclusion
We have introduced the BEHAVIOR Vision Suite (BVS), a novel toolkit designed for the systematic evaluation and comprehensive understanding of computer vision models. BVS enables researchers to control a wide range of parameters across scene, object, and camera levels, facilitating the creation of highly customized datasets. Our experiments highlight BVS's versatility and efficacy through three key applications. First, we show its ability to evaluate model robustness against various domain shifts, underscoring its value in systematically assessing model performance under challenging conditions. Second, we present comprehensive benchmarking of scene understanding models on a unified dataset, illustrating the potential for developing multi-task models using a single BVS dataset. Lastly, we investigate BVS's role in facilitating sim2real transfer for novel vision tasks, including object states and relations prediction. BVS highlights synthetic data's promise in advancing the field, offering researchers the means to generate high-quality, diverse, and realistic datasets tailored to specific needs.
Acknowledgement
We are grateful to SVL members for their helpful feedback and insightful discussions. The work is in part supported by the Stanford Institute for Human-Centered AI (HAI), NSF CCRI #2120095, RI #2338203, ONR MURI N00014-22-1-2740, N00014-21-1-2801, Amazon, Amazon ML Fellowship, and Nvidia.
BibTeX
@InProceedings{ge2024behavior,
title={BEHAVIOR Vision Suite: Customizable Dataset Generation via Simulation},
author={Ge, Yunhao and Tang, Yihe and Xu, Jiashu and Gokmen, Cem and Li, Chengshu and Ai, Wensi and Martinez, Benjamin Jose and Aydin, Arman and Anvari, Mona and Chakravarthy, Ayush K and Yu, Hong-Xing and Wong, Josiah and Srivastava, Sanjana and Lee, Sharon and Zha, Shengxin and Itti, Laurent and Li, Yunzhu and Martin-Martin, Roberto and Liu, Miao and Zhang, Pengchuan and Zhang, Ruohan and Fei-Fei, Li and Wu, Jiajun},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month={June}
year={2024}
pages={22401-22412}
}